Eighty-one percent of IT professionals believe they possess the AI skills their role requires. When researchers at Aalto University actually tested them, 12% did.
That gap — between what we think we know about AI and what we demonstrably know — might be the most expensive cognitive bias in business right now. Because it’s not the people who can’t use AI who are burning money. It’s the people who are certain they can.

Aalto’s researchers found something stranger than a simple skills gap. The classic Dunning-Kruger effect — where the least competent are the most confident — vanishes entirely when AI enters the picture. Everyone overestimates their performance. And the more AI-literate someone is, the worse the overconfidence gets. The researchers attributed it to “cognitive offloading” — the tendency to trust AI output without actually evaluating whether it did what you needed.
You’ve felt this. You’ve prompted ChatGPT, skimmed the output, thought that looks about right, and moved on. We all have. It’s the most natural thing in the world. It’s also the mechanism behind what might be the largest wave of failed corporate investment since the dot-com bubble.
The number everyone's quoting (and getting wrong)
You’ve probably seen the stat: 95% of AI projects fail. It comes from MIT’s Project NANDA report, The GenAI Divide, published July 2025. The number is real. It appears in the study. And it needs serious context that almost nobody provides.
NANDA reviewed 300+ publicly disclosed AI initiatives, interviewed representatives from 52 organisations, and surveyed 153 senior leaders. Their finding: 95% of organisations are getting zero return from generative AI. But “zero return” has a specific definition here — no measurable profit-and-loss impact within six months of pilot. That excludes efficiency gains, cost reductions, customer experience improvements, and anything that doesn’t show up on a P&L statement in half a year.
There’s a bigger problem. Project NANDA builds AI agent infrastructure. Their central finding — that AI fails because it lacks learning, memory, and adaptation — directly describes the product they’re selling. Oxford AI researcher Ajit Jaokar called it “a clever marketing gimmick.” The lead author is listed as a Microsoft employee, not MIT faculty. There’s no peer review.
None of this means the finding is wrong. It means we need a better anchor.
BCG surveyed 1,000 C-suite executives in October 2024 — the most rigorous methodology in the space. Their number: 74% of companies struggle to achieve and scale value from AI. Only 4% consistently generate returns worth talking about.
The rest of the research stacks in the same direction. RAND puts AI project failure at roughly double the rate of non-AI IT projects. Gartner’s 2025 data shows just 11% of organisations can point to clear ROI. S&P Global found 42% of companies abandoned most of their AI initiatives entirely — up from 17% the year before.
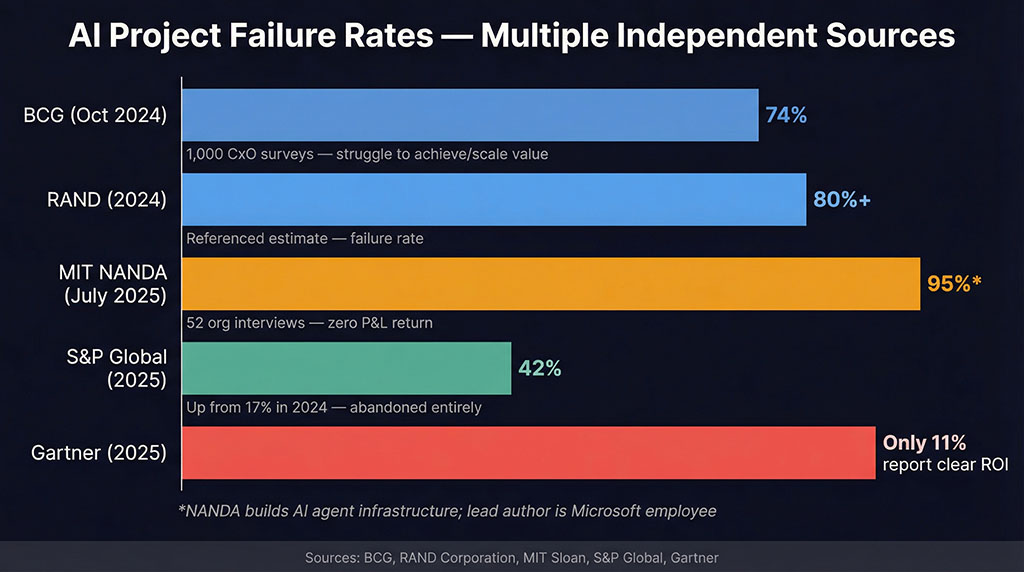
The numbers vary because definitions vary. But the direction is unanimous: most AI deployments don’t produce measurable business results.
And here’s where most coverage of this story stops. AI is failing. Money is being wasted. Isn’t that alarming. Which is roughly as useful as saying “most restaurants fail” without examining what the surviving ones do differently.
Four organisations. One finding. No coordination.
The interesting data isn’t in the failure rate. It’s buried in what the successful minority actually did.
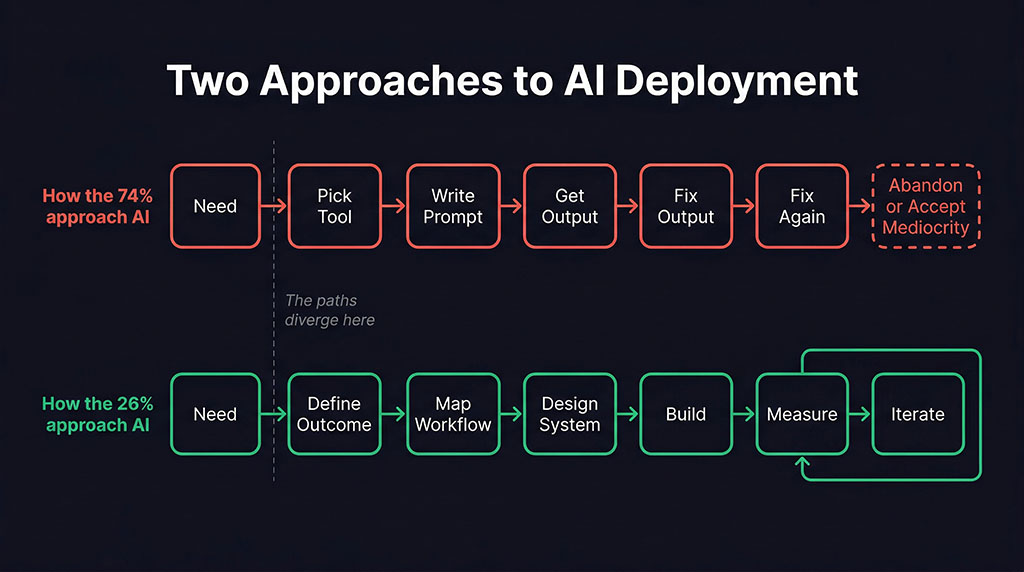
Between 2024 and 2025, four independent research bodies — BCG, McKinsey, RAND, and MIT NANDA — arrived at functionally identical conclusions without coordinating their work. The differentiator between failed AI projects and successful ones was not the model, not the budget, not the team size, and not the prompt quality. It was whether anyone designed the system before they started building it.
McKinsey’s call centre case study makes this uncomfortably concrete. They studied the same AI technology deployed two ways within the same organisation. Passive deployment — adding AI as a tool alongside existing processes — produced 5–10% improvement.
When the team redesigned the entire workflow from scratch around what AI could do, they achieved 60–90% improvement with 80% of queries auto-resolved. Same tech. Same company. Ten to eighteen times the result.
RAND’s analysis, The Root Causes of Failure for AI Projects, found the top cause of failure wasn’t technical capability. It was “miscommunication about what problem to solve.” Not a technology problem. A thinking problem.
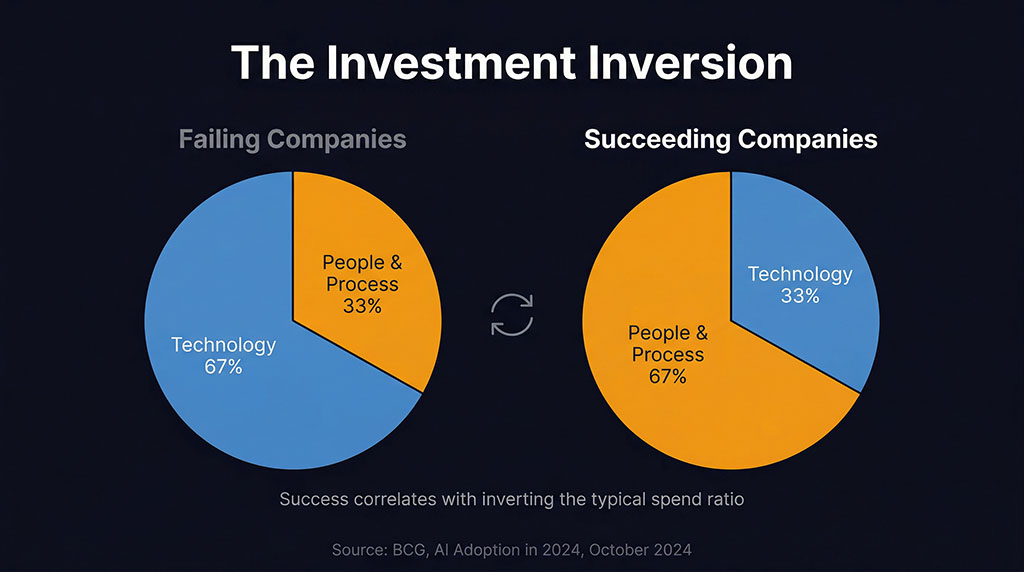
BCG’s data revealed an inversion that should make every AI tool buyer uncomfortable: companies succeeding with AI allocate two-thirds of their effort to people-related capabilities and one-third to technology. Most organisations do the opposite — pouring budget into tools and platforms while spending almost nothing on figuring out what those tools should actually accomplish.
MIT NANDA’s own data reinforces this from a different angle: external vendor solutions — where someone who had already architected the system sold a ready-made tool — succeeded 67% of the time. Internal builds, where teams started from scratch without that design layer, succeeded just 22% of the time.
Four different methodologies. Four different sample populations. The same answer: the gap isn’t in the AI. It’s in the thinking that happens before anyone opens a tool.
"I don't have time to architect anything"
This is where the article is supposed to tell you to slow down, be more strategic, design a comprehensive AI architecture before touching a keyboard.
And you’re already resisting it. Because you’re reading this on a Tuesday with 40 unread emails and a client deliverable due Thursday. You don’t need a framework. You need output. And that urgency — completely legitimate, completely real — is precisely the pressure that produces the 74% failure rate.
But urgency is a permanent condition. There will never be a calm Tuesday where you have four unblocked hours to design your AI architecture. If you wait for that day, you become a statistic.
But “slow down and think first” is also wrong. Or at least incomplete. Because it misidentifies the time cost.
McKinsey’s call centre team didn’t spend more total time on their redesigned workflow. They spent time differently. The passive deployment started fast and then burned weeks on debugging, retraining, and manual corrections — what the MIT study calls the “correction tax.” The redesigned approach spent more time upfront defining the problem, mapping the workflow, and specifying exactly what “working” looked like. Total elapsed time was comparable. The outcome wasn’t.
We went through this exact progression. In 2022, like most people, we were doing one-shot prompts. “Write me a blog post about X.” The output was 80% acceptable — close enough to seem useful, far enough from good to never survive contact with a client. You’d read it and feel that sinking recognition: this sounds like AI wrote it. Every piece needed heavy human editing. We were paying for AI and then paying again to fix what AI produced.
The shift wasn’t learning better prompts. It was stopping to define the system. What does a good outcome actually look like? What does this specific client need? What information does the AI require to produce that outcome consistently?
Once we asked those questions, the architecture followed. We built specialised agents for different content types, each with its own knowledge base and brand guidelines. We created workflows that integrate client strategy before any content gets generated. One coordinating system — we call it “The Brain” — directs specialised tools rather than asking one general tool to do everything.
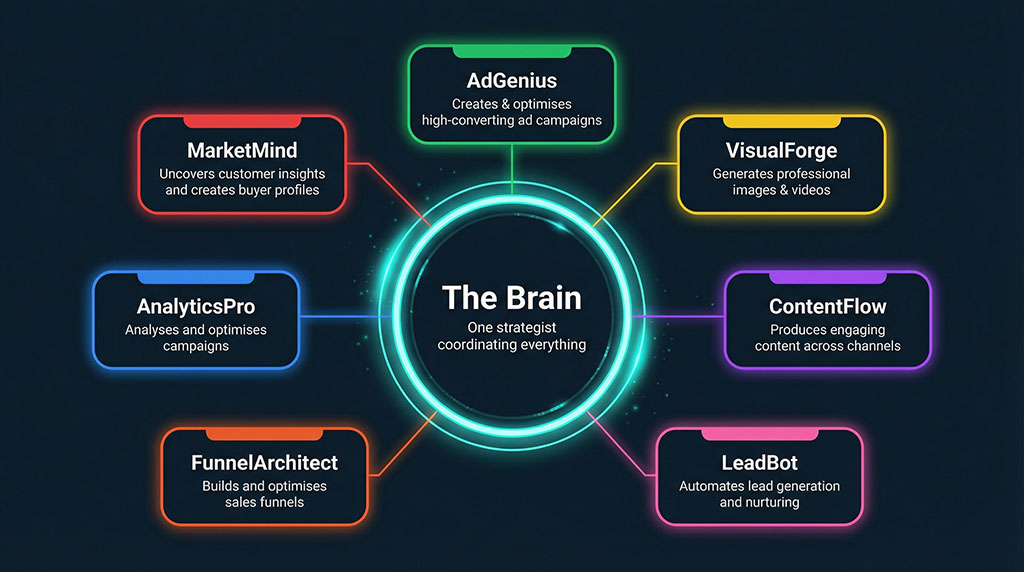
That’s not a technology achievement. Every one of those components uses tools available to anyone. The achievement was in the design — knowing what each component needed to do before we asked AI to do it.
Where the "AI is failing" narrative is right
It would be dishonest to suggest that architectural thinking solves everything. Some of the failure is real, structural, and technology-driven.
Gartner officially placed generative AI in the Trough of Disillusionment in their 2025 Hype Cycle. That’s not editorial commentary — it’s a documented, recurring pattern where technology capability temporarily falls short of inflated expectations before eventually maturing into productivity. We’re in the trough right now.
The MIT study’s “learning gap” is a genuine technical limitation — systems that don’t retain feedback, can’t adapt to context, and fail on edge cases. Sixty percent of users in the NANDA study reported AI tools that repeated errors despite correction. Forty percent reported hallucinations on anything outside common scenarios.
IBM’s 2025 CEO study, covering 2,000 chief executives across 33 countries, found an average AI ROI of 5.9% — below typical cost of capital. Microsoft-funded research from IDC tells a more optimistic story ($3.70 to $10.30 returned per dollar invested), but those figures are self-reported and come from a study commissioned by a company with a direct financial interest in AI adoption looking good. The tension between IBM’s 5.9% and Microsoft’s 370% doesn’t resolve cleanly. Both are probably true for their respective samples, which tells you how wide the variance is.
There’s also a human cost that the ROI figures don’t capture. A Nature study of 381 employees found AI adoption significantly reduces psychological safety and increases depression. Prosci research shows 75% of organisations are at or past the point of change saturation. Failed AI rollouts don’t just waste budget — they erode what researchers call “innovation trust,” making the next transformation effort twice as difficult to gain buy-in for.
The failures are real. The question is whether they’re inevitable.
The expensive middle ground
Most AI failure doesn’t look like dramatic collapse. It looks like mediocrity that’s slightly too expensive to justify.
It looks like a chatbot that answers 60% of questions correctly, which is worse than no chatbot at all because now customers don’t trust any of its answers. It looks like a content system that produces grammatically perfect posts that no one reads because they say nothing a reader couldn’t get from typing the same topic into ChatGPT themselves. It looks like an analytics dashboard that tracks everything and reveals nothing, because nobody defined what decisions the data was supposed to inform.
This is the space where most of the 74% lives. Not catastrophic failure. Expensive adequacy. Tools that work well enough to avoid being cancelled but not well enough to justify their cost.
The pattern underneath all of it — every case study, every failure analysis, every piece of independent research — is the same: someone skipped the design phase. They went from “we should use AI” directly to “build me a thing,” without the intermediate step of defining what “working” looks like in specific, measurable, workflow-integrated terms.
The industry taught this. For a decade, the agency model was built on selling first and figuring out delivery later. You could sell SEO, then outsource the actual work to a team in the Philippines. The client rarely knew the difference.
AI doesn’t work that way. You can’t outsource architectural thinking. A prompt doesn’t get better because someone with a nicer title types it. And the gap between “looks like it works” and “actually works” is visible to every client within about three months — which is why AI agency retention rates are catastrophic.
What "being good at AI" actually means
Back to Aalto University’s overconfidence finding. The researchers discovered that higher AI literacy correlates with more overestimation, not less. Knowing more about AI makes you worse at judging your own output. The reason is cognitive offloading — the better you understand what AI can do, the more likely you are to assume it did do it correctly in this specific instance.
Which means “getting better at AI” in the way most people pursue it — learning more tools, collecting more prompts, watching more tutorials — can actually make the problem worse. You become more fluent in giving instructions without becoming more rigorous in evaluating outcomes.
The 26% who succeed aren’t better prompters. They’re better thinkers. They define the outcome before selecting the tool. They map the workflow before writing the first prompt. They build feedback loops that catch failure before it reaches a customer. They document what works so it’s repeatable, not a one-off accident.
It’s a design discipline, not a technical one. And right now, almost nobody is teaching it — because it doesn’t fit in a tweet thread, it can’t be reduced to a prompt template, and it requires admitting that the hard part of AI was never the AI.
The Aalto researchers called it cognitive offloading. The MIT team called it a learning gap. RAND called it miscommunication about the problem. BCG called it an investment inversion. McKinsey proved it with a single case study where the same technology produced results that varied by 1,800%.
They’re all describing the same thing. And now that you know the pattern, you can’t unsee it in your own work — that moment where confidence in the tool replaced clarity about the outcome. Where fluency felt like competence.
The 12% who actually have the skills aren’t the ones who know the most about AI. They’re the ones who pause long enough to ask what they’re building, and why, before they start. The other 81% already think they’re doing that. That’s the gap.
Your marketing, looked at properly
Thirty minutes on your current setup — what’s working, what’s quietly leaking budget, and what I’d fix first. You’ll leave with a clearer picture whether we work together or not.
Got something specific bugging you? Flag it when you book and I’ll have it looked at before we talk.